2026年最新免费OCR推荐:Umi-OCR,离线批量文字识别神器,图片文档轻松转文本
Umi-OCR 是一款免费、开源且完全离线的文字识别(OCR)软件。它最大的特色在于所有数据都在本地设备上处理,无需联网,在保障数据隐私和安全的同时,提供了极高精度的文字提取能力。Umi-OCR软件绿色免安装版下载地址:Umi-OCR压缩包
它的主要功能如下:
- 截图 OCR:支持截图/上传单张图片进行识别,
- 批量 OCR:批量处理图片,无数量限制,支持 jpg, jpe, jpeg, jfif, png, webp, bmp, tif, tiff 格式。
- 批量文档:批量处理文档,支持 pdf, xps, epub, mobi, fb2, cbz 格式。
- 二维码:截图/粘贴/拖入本地图片,读取其中的二维码、条形码,支持一图多码和 19 种协议。
- 命令行/HTTP 接口:除了软件界面,它还提供了命令行和 HTTP 接口的使用方式,请前往官方库查看(链接在下方版本选择部分)。
下载Umi-OCR
本文提供的是 Windows 平台 Umi-OCR(v2.1.5) 两个引擎插件版本的安装包:Umi-OCR软件绿色免安装版下载地址:https://pan.quark.cn/s/9dabf5ef729c
- Umi-OCR_Paddle_v2.1.5.zip: Paddle 引擎插件版
- Umi-OCR_Rapid_v2.1.5.zip: Rapid 引擎插件版
版本选择
- Paddle 引擎插件版:性能好,速度快,占用率高,适合高配机器。但是不兼容奔腾、赛扬、凌动CPU。
- Rapid 引擎插件版:速度稍慢,内存占用低,适合低配机器,兼容性好。
如果你是开发者,这里是 Umi-OCR 的开源项目仓库:Umi-OCR
安装Umi-OCR
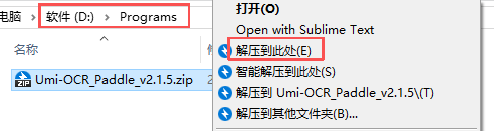
本文中以 Paddle 引擎插件版为例,Rapid 引擎插件版安装步骤完全一致。1) 在要安装的目录中下载 Umi-OCR 压缩包(本文中目录为“D:\Programs”),右击 Umi-OCR_Paddle_v2.1.5.zip,选择“解压到此处”:
2) 双击 Umi-OCR_Paddle_v2.1.5,进入文件夹:

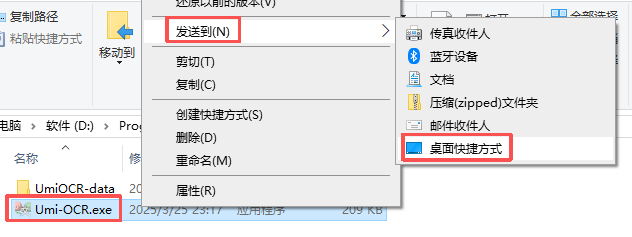
3) 右击 Umi-OCR.exe,选择“发送到”,再选择“桌面快捷方式”,安装完成:
使用Umi-OCR
批量OCR:
1) 双击桌面上的 Umi-OCR.exe - 快捷方式,启动 Umi-OCR:
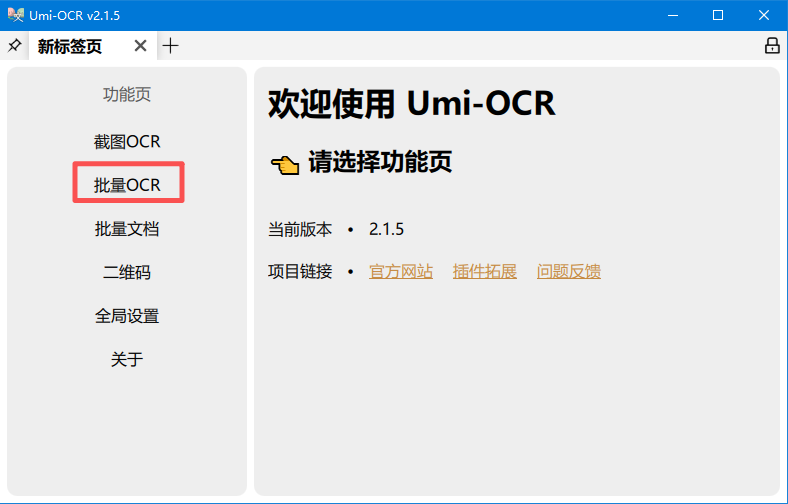
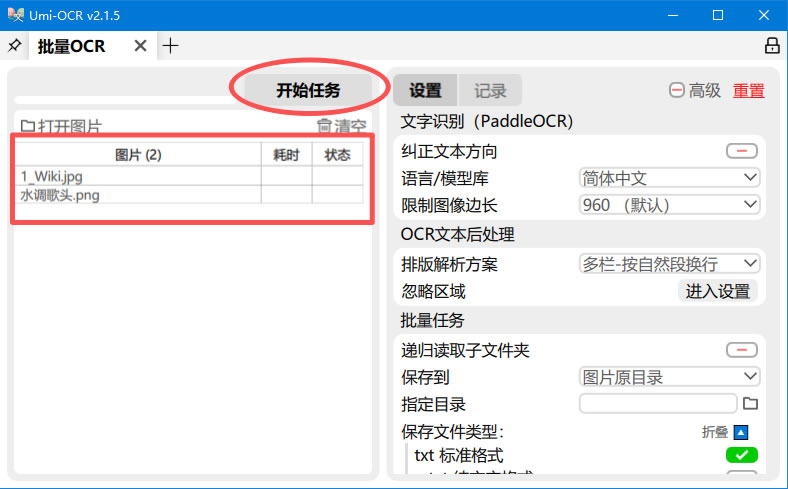
2) 选择左侧功能页的“批量 OCR”:
3) 将图片们或包含所有图片的文件夹拖动到左侧空白区域,可以看到要处理的图片,点击“开始任务”:
PS:如果你不想要 .txt 文件形式保存在本地而是以 md、json 等其他格式文件,可以在右侧“设置”页中,更改“保存文件类型”。
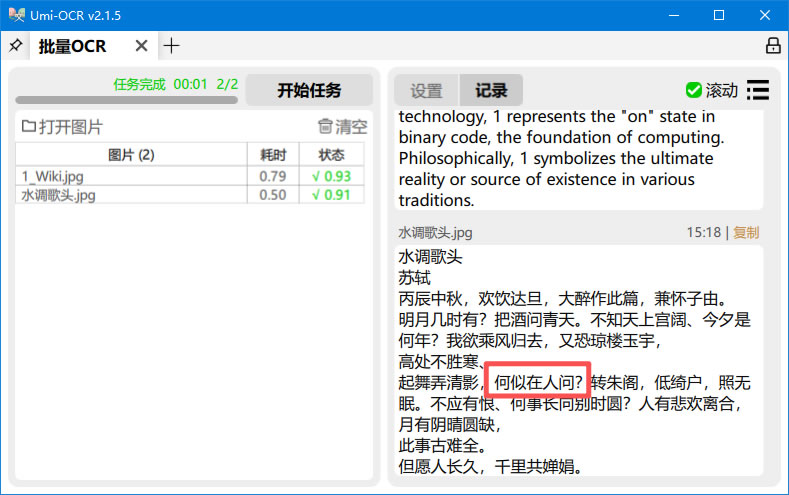
4) 可以看到,在软件界面右侧的“记录”页出现了识别结果,同时,在图片原目录下生成了一个保存识别结果的 .txt 文件:
PS:可以看到识别还是有一定的错误率的(“何似在人问”应该为“何似在人间”),可以在右侧“记录”页中直接修改。
批量文档:
1) 选择左侧功能页的“批量文档”:
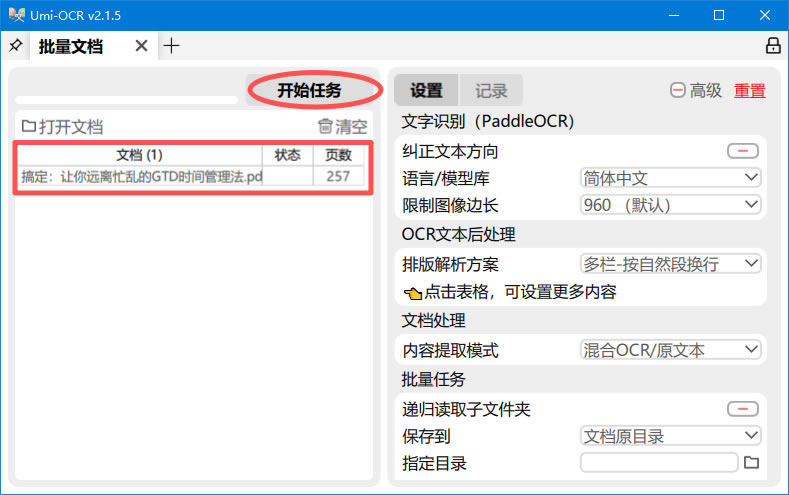
2) 将文档或包含所有文档的文件夹拖动到左侧空白区域,可以看到要处理的文档,点击“开始任务”:
PS:如果你不想要 .layered.pdf 文件形式保存在本地而是以 text.pdf、txt 等其他格式文件,可以在右侧“设置”页中,更改“保存文件类型”。
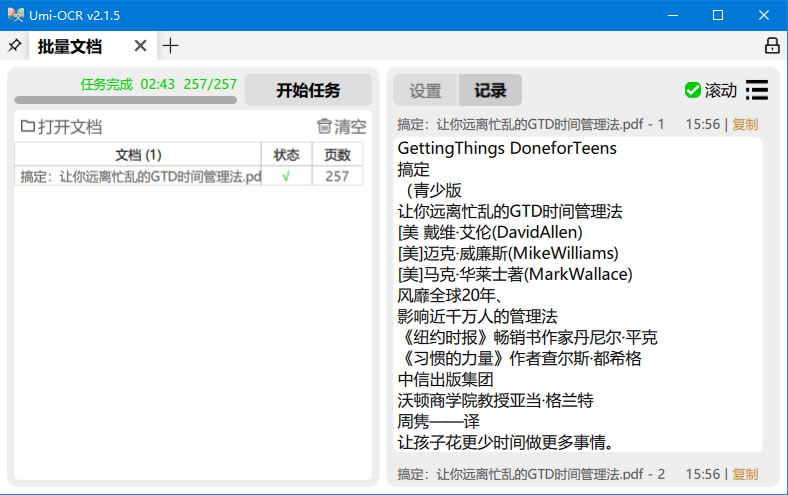
3) 可以看到,在软件界面右侧的“记录”页出现了识别结果,同时,在文档原目录下生成了一个保存识别结果的 .layered.pdf 文件:
Umi-OCR使用注意事项和常见使用问题
注意事项:
1) 善用“忽略区域”功能:如果你经常需要批量识别带有固定页眉、页脚或水印的文档,可以在设置中划定“忽略区域”。这样软件在识别时会自动跳过这些干扰项,就不用你再手动删除了。
2) 关于排版还原功能:
Umi-OCR 的核心强项是“提取文字”。虽然它支持保留段落换行,但它并不是一个完美的“格式还原”工具。如果你需要把扫描版 PDF 完美转换成可编辑的 Word 且保持原格式(包括表格、图片位置等),它可能无法满足 100% 的需求,更适合提取纯文本内容。
3) 关于正确率:
作为一个离线且相对轻量的文字识别工具,有一定的错误率是很正常的,而影响识别正确率的因素还有很多,比如图片大小、清晰程度、文字字体、是否有背景等等,请谨慎预期。
常见问题解答:
1) 执行 OCR 时报错 0xc0000142、[Error] OCR init fail,怎么办?大概率是 CPU 不兼容 Paddle,请换用 Rapid 版本。
2) 弹窗报错 Umi-OCR.exe 已停止工作,怎么办?
此问题常见于:软件已经在 win10 使用过,然后原封不动复制到 win7 上,导致配置冲突。删除 UmiOCR-data/.pre_settings 配置文件即可。
3) 打开软件时,弹出错误弹窗:计算机中丢失 api-ms-win-crt-runtime-l1-1-0.dll,怎么办?
这可能是因为缺少 VC 运行库,安装 VC 运行库即可,这是它的官方链接:https://aka.ms/vs/17/release/vc_redist.x64.exe。
总结
无论你是需要快速提取屏幕文字的学生党,还是处理大量文档的职场精英,Umi-OCR 都凭借其高精度、零门槛和绝对安全的特性,交出了一份令人满意的答卷。现在就来下载试一试吧,相信它一定能满足你的要求(⁎˃ᴗ˂⁎)
相关文章
- CATIA是什么软件?2026年最新CATIA下载和安装免费全攻略(新手必看)
- PotPlayer下载电脑端:2026年最强免费播放器,告别卡顿与广告!
- 2026年最佳录屏软件推荐:EV录屏免费下载,Windows/Mac电脑怎么录屏全攻略
- 2026年最强AI工作台!Cherry Studio下载全解析:支持多模型客户端,跨平台免费用
- Reqable是什么?2026年最强HTTP开发工具推荐,小白也能轻松上手的抓包软件
- 2026最新洛雪音乐官网指南:洛雪音乐下载、音源配置、安装一站式教程
- 【2026最新】MinGW下载安装:零基础搭建C语言开发环境一站式搞定
- 【2026最新】Adobe Lightroom Classic 15.3最新版怎么装?LrC安装教程与避坑指南
- 【2026最新】Adobe InDesign下载安装教程:Id2026专业排版神器一键安装
- 【2026最新】Bandizip专业破解版(亲测无毒)下载安装保姆级教程(附安装包+图文)
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: