Java Queue队列的用法(非常全面)
Queue 本身是一种先入先出(FIFO)的模型,与日常生活中的排队模型很相似。在 Java 语言中,Queue 是一个接口,它只是定义了一个 Queue 应该具有哪些功能。
Queue 有多个实现类,有的类采用线性表来实现的,有的则是基于链表实现的。有些类是多线程安全的,有些则不是。
Java 中具有 Queue 功能的类主要有如下几个:AbstractQueue、ArrayBlockingQueue、Concurrent LinkedQueue、LinkedBlockingQueue、DelayQueue、LinkedList、PriorityBlockingQueue、PriorityQueue和 ArrayDqueue。图 1 给出了部分常用的 Queue 的类。
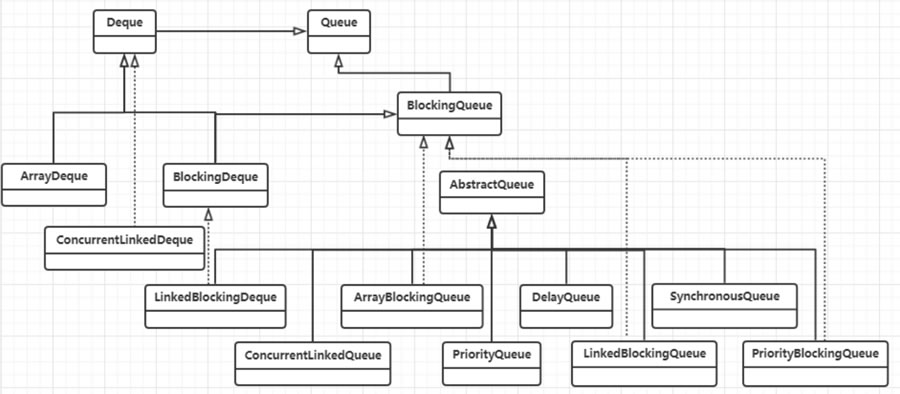
图1 Queue类图
本文我们重点介绍 PriorityQueue 的用法。
PriorityQueue 并不遵循 FIFO(先入先出)原则,它会根据队列元素的优先级来调整顺序,优先级最高的元素最先出。由此可以推断,PriorityQueue 要么提供一个Comparator 来对元素进行比较,要么元素本身需要实现了接口 Comparable。下面通过对源码的解析,来验证这个推断。
最小堆是一种经过排序的完全二叉树,其中任一非终端结点数值均不大于其左孩子和右孩子结点的值。可以得出结论,如果一棵二叉树满足最小堆的要求,那么,堆顶(根结点)也就是整个序列的最小元素。最小堆的例子如图 2 所示。
可以注意到,20 的两个子结点 31、21,和它的叔结点 30 并没有严格的大小要求。以广度优先的方式从根结点开始遍历,可以构成序列:
现在可以思考一个问题,对于给定的序列,如何让它满足最小堆的性质?例如:[20, 10, 12, 1, 7, 32, 9] 构成的二叉树如图 3 所示。
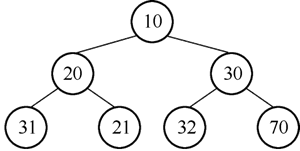
图2 最小堆
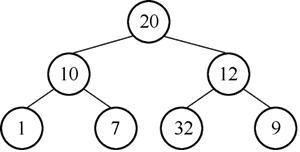
图3 二叉树示例图
这里提供了一个如何把一个二叉树调整为最小堆方法,这个方法主要有下面几个步骤:
下面我们应用该方法对之前的数列进行调整:
因为数列 [20,10,12,1,7,32,9] 的长度为 7,所以 size/2-1=2,倒序遍历过程是 12->10->20。
1) 12 的左孩子为 32,右孩子为 9,12>9,进行沉降,结果如图 4 所示。
2) 10 的左孩子为 1,右孩子为 7,10>1,进行沉降,结果如图 5 所示。
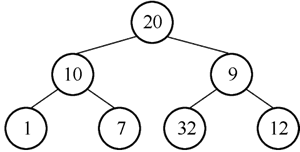
图4 结点12下沉后的二叉树
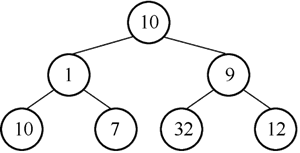
图5 结点10下沉后的二叉树
3) 20 的左孩子为 1,右孩子为 9,20>1,进行沉降,结果如图 6 所示。
4) 20 的左孩子为 10,右孩子为 7,20>7,进行沉降,得到最终结果如图 7 所示。
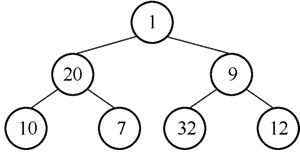
图6 结点 20 下沉后的二叉树
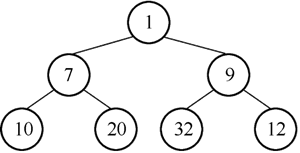
图7 结点 20 继续下沉后的二叉树
满足最小堆的要求,此时,得出的序列为 [1,7,9,10,20,32,12]。
该实现的流程也就是 PriorityQueue 的 heapify 方法的流程,heapify 方法负责把序列转化为最小堆,也就是所谓的建堆。其源码如下所示:
如果 comparator 不为 null,那么调用 comparator 进行比较;反之,则把元素视为 Comparable 进行比较。如果元素没有实现 Comparable 接口,那么会抛出 ClassCastException。无论使用哪种方法进行比较,执行的算法都是一样的。
这里只选取其中之一进行讲解,Java 代码如下:
为什么新加入的结点需要做上浮呢?这是因为新添加的结点初始位置是在整个数列的末位,在二叉树中,它一定是叶子结点,当它的值比父结点要小时,就不再满足最小堆的性质了,所以,需要进行上浮操作。
grow 方法有如下两个功能:
与 siftDown 一样,它也有两种等效的实现路径,这里只做 shifUpUsingComparator 的解析:
1) 执行添加 19 后的二叉树如图 9 所示。
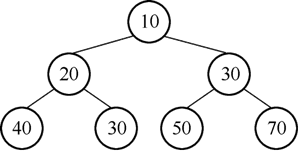
图8 最小堆示例
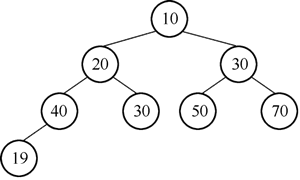
图9 添加结点 19 后的二叉树
2) 19<40,与40交换位置,交换后的二叉树如图 10 所示。
3) 19<20,与20交换位置,交换后的二叉树如图 11 所示。
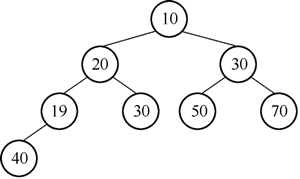
图10 交换19与40后的二叉树
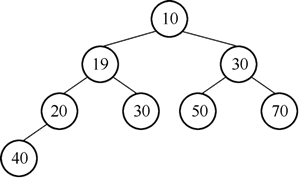
图11 交换19与20后的二叉树
4) 19>10,终止上浮操作,最后得到的数列为:[10,19,30,20,30,50,70,40]。该数列满足了最小堆的性质。
但是,当堆顶元素移除后,如果不做调整,那么新的堆顶会变成原来堆顶的左孩子,所以,移除后需要对二叉树重新调整。根据最小堆的性质,可以证明:移除最小堆任意叶子结点,最小堆性质不变。
因为数组的末位结点在最小堆内,一定是叶子结点,所以,这里可以使用末位结点来替换根结点,然后进行沉降操作。这样做有以下三个好处:
以满足最小堆的数列 [1, 7, 9, 10, 20, 32, 12 ]为例,其构建的最小堆如图 12 所示。
1) 执行poll(),备份并移除结点1,移除后把堆的最后一个结点12移动到堆顶,移除后的二叉树如图13所示。
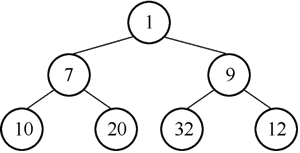
图12 最小堆示例
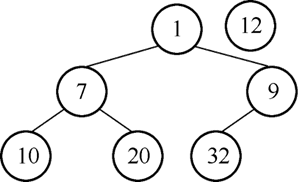
图13 用12替换结点1
2) 执行 siftDonw(0,结点 12),即把结点 12 视为堆顶,进行沉降。12 的左孩子为 7,右孩子为 9,12>7,向左侧沉降,结果如图 14 所示。
3)12 的左孩子为 10,右孩子为 20,12>10,向左侧沉降,结果如图 15 所示。
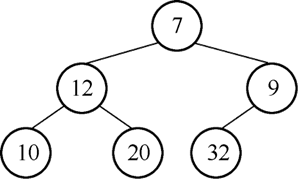
图14 用12替换结点1沉降
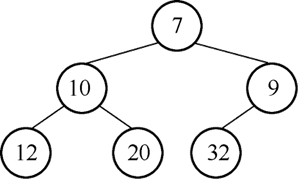
图15 用12向左沉降
4) 12 为叶子结点,操作结束,最终得出的数列为:[7,10,9,12,20,32]。
声明:《Java系列教程》为本站“54笨鸟”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
Queue 有多个实现类,有的类采用线性表来实现的,有的则是基于链表实现的。有些类是多线程安全的,有些则不是。
Java 中具有 Queue 功能的类主要有如下几个:AbstractQueue、ArrayBlockingQueue、Concurrent LinkedQueue、LinkedBlockingQueue、DelayQueue、LinkedList、PriorityBlockingQueue、PriorityQueue和 ArrayDqueue。图 1 给出了部分常用的 Queue 的类。
图1 Queue类图
本文我们重点介绍 PriorityQueue 的用法。
PriorityQueue 并不遵循 FIFO(先入先出)原则,它会根据队列元素的优先级来调整顺序,优先级最高的元素最先出。由此可以推断,PriorityQueue 要么提供一个Comparator 来对元素进行比较,要么元素本身需要实现了接口 Comparable。下面通过对源码的解析,来验证这个推断。
1. 成员变量
PriorityQueue 的主要成员变量有:transient Object[] queue; /* 存值数组 */ private int size = 0; /* 元素数量 */ /*比较器,可以为null,当为null时E必须实现Comparable */ private final Comparator<? super E> comparator;由此可见,这个类提供了一个 comparator 成员变量。同时,可以看到,PriorityQueue 的存储结构是个数组。因此,数据增加的同时,就必须考虑到数组的扩容。
2. heapify方法和最小堆
在讲解 PriorityQueue 之前,需要先熟悉一个有序数据结构:最小堆。最小堆是一种经过排序的完全二叉树,其中任一非终端结点数值均不大于其左孩子和右孩子结点的值。可以得出结论,如果一棵二叉树满足最小堆的要求,那么,堆顶(根结点)也就是整个序列的最小元素。最小堆的例子如图 2 所示。
可以注意到,20 的两个子结点 31、21,和它的叔结点 30 并没有严格的大小要求。以广度优先的方式从根结点开始遍历,可以构成序列:
[10,20,30,31,21,32,70]
反过来,可以推演出,序列构成二叉树的公式是:对于序列中下标为 i(此处指的下标从 0 开始)的元素,左孩子的下标为left(i)=i*2+1,右孩子的下标为right(i)=left(i)+1。现在可以思考一个问题,对于给定的序列,如何让它满足最小堆的性质?例如:[20, 10, 12, 1, 7, 32, 9] 构成的二叉树如图 3 所示。
图2 最小堆
图3 二叉树示例图
这里提供了一个如何把一个二叉树调整为最小堆方法,这个方法主要有下面几个步骤:
- 倒序遍历数列。
- 对二叉树中的元素挨个进行沉降处理,沉降过程为:把遍历到的结点与左右子结点中的最小值比对,如果比最小值要大,那么和该子结点交换数据,反之则不做处理,继续 1 过程。
- 沉降后的结点,再次沉降,直到叶子结点。同时,因为下标在 size/2 之后的结点都是叶子结点,所以可以从 size/2-1 位置开始倒序遍历,从而减少比较次数。
下面我们应用该方法对之前的数列进行调整:
因为数列 [20,10,12,1,7,32,9] 的长度为 7,所以 size/2-1=2,倒序遍历过程是 12->10->20。
1) 12 的左孩子为 32,右孩子为 9,12>9,进行沉降,结果如图 4 所示。
2) 10 的左孩子为 1,右孩子为 7,10>1,进行沉降,结果如图 5 所示。
图4 结点12下沉后的二叉树
图5 结点10下沉后的二叉树
3) 20 的左孩子为 1,右孩子为 9,20>1,进行沉降,结果如图 6 所示。
4) 20 的左孩子为 10,右孩子为 7,20>7,进行沉降,得到最终结果如图 7 所示。
图6 结点 20 下沉后的二叉树
图7 结点 20 继续下沉后的二叉树
满足最小堆的要求,此时,得出的序列为 [1,7,9,10,20,32,12]。
该实现的流程也就是 PriorityQueue 的 heapify 方法的流程,heapify 方法负责把序列转化为最小堆,也就是所谓的建堆。其源码如下所示:
private void heapify(){
for(int i=(size>>>1)-1;i>=0;i--)
siftDown(i,(E)queue[i]);
siftDown(i,(E)queue[i]);
}
siftDown方法也就是之前提过的沉降方法。3. siftDown(k,x)方法
siftDown方法用于沉降,根据 comparator 成员变量是否为 null,它的执行方式略有不同。如果 comparator 不为 null,那么调用 comparator 进行比较;反之,则把元素视为 Comparable 进行比较。如果元素没有实现 Comparable 接口,那么会抛出 ClassCastException。无论使用哪种方法进行比较,执行的算法都是一样的。
这里只选取其中之一进行讲解,Java 代码如下:
private void siftDownUsingComparator(int k, E x){
int half = size >>> 1; /*只查找非叶子结点*/
while (k < half) {
int child = (k << 1) + 1; /* 左孩子 */
Object c = queue[child];
int right = child + 1; /* 右孩子 */
/*取左右孩子中的最小者*/
if (right < size && comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
/*父结点比最小孩子小说明满足最小堆,结束循环*/
if (comparator.compare(x, (E) c) <= 0)
break;
/*交换父结点和最小孩子位置,继续沉降*/
queue[k] = c;
k = child;
}
queue[k] = x;
}
注释已经解释清楚了代码的执行逻辑,其目的是把不满足最小堆条件的父结点一路沉到最底部。从以上代码可以看出,siftDown 的时间复杂度不会超出O(log2n)。4. offer(e)方法
PriorityQueue 的 offer 方法用于把数据入队,其源码实现如下所示:
public boolean offer(E e){
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length) /*容量不够时,对数组做扩容*/
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e; /*初始化队列*/
else
siftUp(i, e); /* 上浮结点 */
return true;
}
从实现源码中可以观察到它有如下几个特性:- 不能存放 null 数据。
- 与 ArrayList 留有扩容余量不同,当 size 达到数组长度极限时,才执行扩容(grow 方法)。
- 当队列中有数据时,会执行结点上浮(siftUp),把优先级更高的数据放置在队头。
为什么新加入的结点需要做上浮呢?这是因为新添加的结点初始位置是在整个数列的末位,在二叉树中,它一定是叶子结点,当它的值比父结点要小时,就不再满足最小堆的性质了,所以,需要进行上浮操作。
5. grow(minCapacity)方法
grow方法用于对 PriorityQueue 进行扩容,Java 代码如下所示:
private void grow ( int minCapacity){
int oldCapacity = queue.length;
//长度较小则扩容一倍,否则扩容50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1));
//溢岀校验
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity ( int minCapacity){
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
grow 方法有如下两个功能:
- 扩容。扩容策略是,如果旧容量小于 64,那么增加一倍 +2,否则增加 50%。
- 溢出校验。如果小于 0,那么认为溢出,容量最大能支持到最大正整数。
6. siftUp(k,x)方法
siftUp方法用于上浮结点。新加入的结点一定在数列末位,为了让数列满足最小堆性质,需要对该结点进行上浮操作。与 siftDown 一样,它也有两种等效的实现路径,这里只做 shifUpUsingComparator 的解析:
private void siftUpUsingComparator(int k, E x){
while (k > 0) {
/*找到父结点*/
int parent = (k - 1) >>> 1;
Object e = queue[parent];
/*父结点较小时,满足最小堆性质,终止循环*/
if (comparator.compare(x, (E) e) >= 0)
break;
/*交换新添加的结点和父结点位置,继续上浮操作*/
queue[k] = e;
k = parent;
}
queue[k] = x;
}
为了更容易地理解这个方法,下面通过一个例子来详细的解析,假设有最小堆数列[10,20,30,40,30,50,70],构成最小堆如图 8 所示。1) 执行添加 19 后的二叉树如图 9 所示。
图8 最小堆示例
图9 添加结点 19 后的二叉树
2) 19<40,与40交换位置,交换后的二叉树如图 10 所示。
3) 19<20,与20交换位置,交换后的二叉树如图 11 所示。
图10 交换19与40后的二叉树
图11 交换19与20后的二叉树
4) 19>10,终止上浮操作,最后得到的数列为:[10,19,30,20,30,50,70,40]。该数列满足了最小堆的性质。
7. poll()方法
poll方法用来检索并移除此队列的头,它的实现源码如下所示:
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0]; /* 获取队头 */
E x = (E) queue[s]; /* 获取队尾 */
queue[s] = null; /* 清空队尾 */
//队尾和队头不是同一个结点的时候,进行沉降操作
if (s != 0)
siftDown(0, x);
return result;
}
通过之前的间接可以知道,最小堆虽然不保证数列的顺序,但其堆顶元素始终是最小元素,恰好,PriorityQueue 只要求出队的对象优先级最高,所以,poll 方法只需要直接获取堆顶元素即可达到目的。但是,当堆顶元素移除后,如果不做调整,那么新的堆顶会变成原来堆顶的左孩子,所以,移除后需要对二叉树重新调整。根据最小堆的性质,可以证明:移除最小堆任意叶子结点,最小堆性质不变。
因为数组的末位结点在最小堆内,一定是叶子结点,所以,这里可以使用末位结点来替换根结点,然后进行沉降操作。这样做有以下三个好处:
- 不需要整个重新排列数组。
- 不破坏最小堆性质。
- 沉降操作时间复杂度不会超过O(log2n),效率得以保证。
以满足最小堆的数列 [1, 7, 9, 10, 20, 32, 12 ]为例,其构建的最小堆如图 12 所示。
1) 执行poll(),备份并移除结点1,移除后把堆的最后一个结点12移动到堆顶,移除后的二叉树如图13所示。
图12 最小堆示例
图13 用12替换结点1
2) 执行 siftDonw(0,结点 12),即把结点 12 视为堆顶,进行沉降。12 的左孩子为 7,右孩子为 9,12>7,向左侧沉降,结果如图 14 所示。
3)12 的左孩子为 10,右孩子为 20,12>10,向左侧沉降,结果如图 15 所示。
图14 用12替换结点1沉降
图15 用12向左沉降
4) 12 为叶子结点,操作结束,最终得出的数列为:[7,10,9,12,20,32]。
声明:《Java系列教程》为本站“54笨鸟”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: