Spring Data JPA简介与使用
Spring Data JPA 是 Spring Data 大家族中的一员,可以轻松实现基于 JPA 的存储库。Spring Data JPA 主要基于 JPA 提供对数据访问层的增强支持。借助它可以使构建设计数据访问技术的Spring应用程序变得更加容易。
在相当长的一段时间内,实现应用程序的数据访问层一直很麻烦。必须编写大量的样板代码来执行简单查询以及执行分页和审计。
Spring Data JPA 旨在通过减少实际需要的工作量来显著改善数据访问层的实现。作为开发人员可以只编写 Repository 接口,包括自定义查找器方法,Spring 将自动提供对应的实现。Spring Data 生态如图 1 所示。
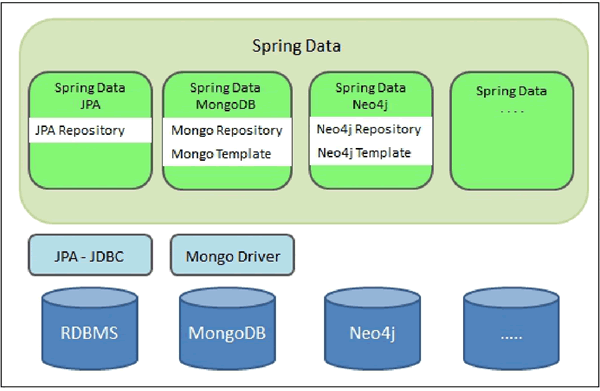
图 1 Spring Data生态示意图
Spring Data JPA 是 Spring Data 对 JPA 规范的封装,在其规范下提供 Repository 层的实现,并提供配置项用以切换具体实现规范的 ORM 框架。Spring Data JPA、JPA 以及基于 JPA 规范的 ORM 框架,如图 2 所示。
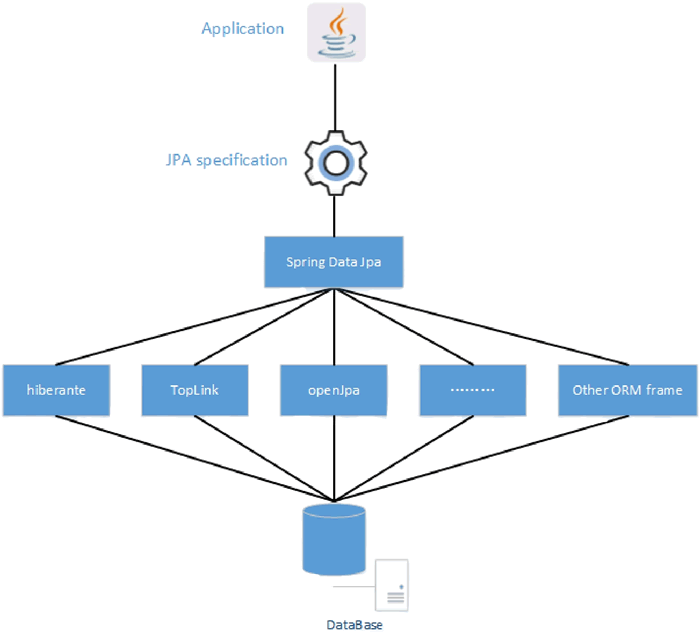
图2 Spring Data JPA、JPA与各ORM框架
基于接口查询,首先要关注的接口为“Repository”。Repository 是 Spring Data JPA 的核心接口。它需要领域实体类以及实体类的 ID 类型作为类型参数进行管理。该类主要作为标记接口,用以捕获要使用的类型并帮助发现扩展该接口的子接口。
另外还有更为具体的 CrudRepository 以及 JpaRepository,这两个类包含具体的基础 CURD 方法。
Repository.java:
Spring Data JPA 将在应用运行时对方法名进行解析,解析的过程为:去掉 findBy 等前缀,再根据剩下的字段名与关键字,生成对应查询的代码实现。关键字及示例参考表 1 所示。
JpaSpecificationExecutor.java:
Specification.java:
UserRepository.java:
声明:《Java系列教程》为本站“54笨鸟”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
在相当长的一段时间内,实现应用程序的数据访问层一直很麻烦。必须编写大量的样板代码来执行简单查询以及执行分页和审计。
Spring Data JPA 旨在通过减少实际需要的工作量来显著改善数据访问层的实现。作为开发人员可以只编写 Repository 接口,包括自定义查找器方法,Spring 将自动提供对应的实现。Spring Data 生态如图 1 所示。
图 1 Spring Data生态示意图
Spring Data JPA 是 Spring Data 对 JPA 规范的封装,在其规范下提供 Repository 层的实现,并提供配置项用以切换具体实现规范的 ORM 框架。Spring Data JPA、JPA 以及基于 JPA 规范的 ORM 框架,如图 2 所示。
图2 Spring Data JPA、JPA与各ORM框架
基于 JpaRepository 接口查询
Spring Data JPA 框架的目标之一就在于简化数据访问层的开发过程,消除项目中的样板代码。基于接口的查询方式是实现代码简化的有效方法。通过基于接口的查询方式进行开发,框架将在应用运行时,根据接口名的定义生成包含对应 SQL 语句的代理实例。这免去了手写 SQL 的环节,进而实现了简化。基于接口查询,首先要关注的接口为“Repository”。Repository 是 Spring Data JPA 的核心接口。它需要领域实体类以及实体类的 ID 类型作为类型参数进行管理。该类主要作为标记接口,用以捕获要使用的类型并帮助发现扩展该接口的子接口。
另外还有更为具体的 CrudRepository 以及 JpaRepository,这两个类包含具体的基础 CURD 方法。
Repository.java:
@Indexed
public interface Repository<T, ID> {
}
JpaRepository.java:
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
//查询所有数据
@Override
List<T> findAll();
//查询所有数据,并以排序选项进行排序后返回
@Override
List<T> findAll(Sort sort);
//根据id查询集合
@Override
List<T> findAllById(Iterable<ID> ids);
//保存所有数据
@Override
<S extends T> List<S> saveAll(Iterable<S> entities);
//将之前的改动刷写进数据库
void flush();
//保存并立刻刷写当前实体
<S extends T> S saveAndFlush(S entity);
//删除给出的集合
void deleteInBatch(Iterable<T> entities);
//批量删除
void deleteAllInBatch();
//根据id查询目标实体
T getOne(ID id);
//根据实例查询
@Override
<S extends T> List<S> findAll(Example<S> example);
//根据实例查询并排序
@Override
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
使用基于接口的查询方式,首先需要定义查询表对应的实体。实体示例 Patient.java 如下:
@Entity
@Table(name = "patient")
@Data
@Accessors(chain = true)
public class Patient implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@Id
@Column(name = "id", nullable = false)
private Integer id;
/**
* 名
*/
@Column(name = "first_name")
private String firstName;
/**
* 姓
*/
@Column(name = "last_name")
private String lastName;
/**
* 身高
*/
@Column(name = "height")
private BigDecimal height;
/**
* 体重
*/
@Column(name = "body_weight")
private BigDecimal bodyWeight;
/**
* BMI指数
*/
@Column(name = "BMI")
private BigDecimal BMI;
}
通过注解 @Entity 标注该类为实体类,通过 @Table(name = "patient") 标注该类的表明为 patient。类的主键需要使用 @Id 注解进行标注,另外需要@Column 注解标注对应的字段名。实体查询类 PatientRepository.java 如下:
public interface PatientRepository extends JpaRepository<Patient, Integer> {
List<Patient> findByFirstName(String firstName);
Patient findByFirstNameAndLastName(String firstName, String lastName);
List<Patient> findByHeightGreaterThan(BigDecimal height);
}
PatientRepository.java 对应测试代码如下:
@Test
public void testJpaRepository(){
List<patient> san=patientRepository.findByFirstName("san");
assert san!=null;
assert san.size()>0;
Patient lisi=patientRepository.findByFirstNameAndLastName("si","li");
assert lisi!=null;
List<Patient> tallPatients=patientRepository.findByHeightGreaterThan(new BigDecimal(190));
assert tallPatients!=null;
assert tallPatients.size()==0;
}
从以上示例可以观察到,完成一个查询仅需要定义一个 findBy{:column} 格式的方法名。事实上,findBy 可以替换为 getBy、readBy 或者直接去掉。Spring Data JPA 将在应用运行时对方法名进行解析,解析的过程为:去掉 findBy 等前缀,再根据剩下的字段名与关键字,生成对应查询的代码实现。关键字及示例参考表 1 所示。
| 关键字 | 示例 | JPQL语句片段 |
|---|---|---|
| And | findByLastnameAndFirstname | ... where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | ... where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals |
findByFirstname,findByFirstnameIs,findByFirstname Equals |
... where x.firstname = ?1 |
| Between | findByStartDateBetween | ... where x.startDate between?1 and?2 |
| LessThan | findByAgeLessThan | ... where x.age<?1 |
| LessThanEqual | findByAgeLessThanEqual | ... where x.age<=?1 |
| GreaterThan | findByAgeGreaterThan | ... where x.age>?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | ... where x.age>= ?1 |
| After | findByStartDateAfter | ... where x.startDate>?1 |
| Before | findByStartDateBefore | ... where x.startDate<? 1 |
| IsNull | findByAgelsNull | ... where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | ... where x.age not null |
| Like | findByFirstnameLike | ... where x.firstname like?1 |
| NotLike | findByFirstnameNotLike | ... where x.firstname not like ? 1 |
| StartingWith | findByFirstnameStartingWith | ... where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | ... where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | ... where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | ... where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | ... where x.lastname <> ? 1 |
| In | findByAgeIn(Collection<Age> ages) | ... where x.age in?1 |
| NotIn | findByAgeNotIn(Collection<Age> age) | ... where x.agenot in? 1 |
| TRUE | findByActiveTrue() | ... where x.active = true |
| FALSE | findByActiveFalse() | ... where x.active = false |
| IgnoreCase | findByFirstnamelgnoreCase | ... where UPPER(x.firstame) = UPPER(?1) |
基于JpaSpecificationExecutor接口查询
上面我们介绍的 JpaRepository 接口固然十分方便,但用于实现逻辑更为复杂的需求,便显得捉襟见肘了。使用 JpaRepository 接口更适用于参数不多、逻辑简单的查询场景。为了补足 JpaRepository 难以实现的部分,Spring Data JPA 另外提供了 JpaSpecificationExecutor 这一接口供复杂查询的场景使用。JpaSpecificationExecutor.java:
public interface JpaSpecificationExecutor<T> {
//根据spec查询出一个Optional的实体类
Optional<T> findOne(@Nullable Specification<T> spec);
//根据spec查询出对应实体列表
List<T> findAll(@Nullable Specification<T> spec);
//根据spec查询出实体分页
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
//根据spec查询出对应实体列表,并根据给出的排序条件进行排序
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
//查询满足spec条件的实体列表长度
long count(@Nullable Specification<T> spec);
}
其中 Specification 接口提供的 toPredicate() 方法,供开发人员灵活构造复杂的查询条件。Specification.java:
public interface Specification<T> extends Serializable {
@Nullable
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder);
//省略若干方法
}
在基于接口查询的开发过程中,往往会在实体的 Repository 接口类同时继承 JpaRepository 与 JpaSpecificationExecutor,以赋予该 Repository 接口能同时完成简单查询与复杂查询的能力。UserRepository.java:
public interface UserRepository extends JpaRepository<User, Integer>,JpaSpecificationExecutor<User> {
}
实体类User.java:
@Entity
@Table(name = "user")
@Data
@Accessors(chain = true)
public class User implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@Id
@Column(name = "id", nullable = false)
private Integer id;
/**
* 用户名
*/
@Column(name = "name")
private String name;
/**
* 账户名
*/
@Column(name = "account")
private String account;
/**
* 密码
*/
@Column(name = "password")
private String password;
/**
* 创建时间
*/
@Column(name = "create time")
private LocalDateTime createTime;
@OneToOne
private Vehicle vehicle;
}
设想一个场景,需要创建一个查询方法用于查询符合条件的用户。例如,给出一个时间区间与一个关键字,查询出创建时间在该区间内的所有用户,并且用户名包含关键字。如果使用 JpaRepository 实现,则示例代码如下:
@Test
public void testJpaRepositoryComplicated(){
//根据时间与关键字查询
List<User> queryWithTimeAndKeyWord=getUser(LocalDateTime.of(2019,1,1,0,0,0),LocalDateTime.of(2020,1,1,0,0,0),"陈");
assert queryWithTimeAndKeyWord !=null;
//根据时间查询
List<User> queryWithTime=getUser(LocalDateTime.of(2019,1,1,0,0,0),LocalDateTime.of(2020,1,1,0,0,0),null);
assert queryWithTime!=null;
//普通查询
List<User> query=getUser(null,null,"张");
assert query!=null;
}
//以下示例为不推荐的查询实现方式,属于错误示范
private List<User> getUser(@Nullable LocalDateTime start,@Nullable LocalDateTime end,@Nullable String keyword){
//String.format中%为特殊字符需要再加一个%进行转义,以下格式化的结果为% {keyword} %
String nameLike = keyword == null ? null : String. format ("%%%s%%", keyword);
if (start != null && end != null && !StringUtils.isEmpty(nameLike)) {
//查询条件同时包含时间与关键字
return userRepository.findByCreateTimeBetweenAndNameLike(start,end,nameLike);
}else if(start! =null&&end! =null&&StringUtils.isEmpty(nameLike)){
//查询条件仅包含时间
return userRepository.findByCreateTimeBetween(start,end);
}else if((start==null||end==null)&&!StringUtils.isEmpty(nameLike)){
//查询条件仅包含关键字
return userRepository.findByNameLike(keyword);
}else{
return userRepository.findAll();
}
}
可以看到,这一段代码的实现并不优雅,需要针对不同情况定义不同的 Repository 接口。如果参数进一步增加,对应 Repository 接口内的方法数量将膨胀到难以维护的程度。使用 JpaSpecificationExecutor 实现同样的功能,示例代码如下:
@Test
public void testJpaSpecificmtionExecutor(){
//根据时间与关键字查询
List<User> queryWithTimeAndKeyWord = getUserWithJpaSpecificationExecutor(LocalDateTime.of(2019,1,1,0,0,0),LocalDateTime.of(2020,1,1,0,0,0),"陈");
assert queryWithTimeAndKeyWord!=null;
//根据时间查询
List<Use:r>queryWithTime=getUserWithJpaSpecificationExecutor(LocalDateTime.of(2019,1,1,0,0,0),LocalDateTime.of(2020,1,1,0,0,0),null);
assert queryWithTime!=null;
//普通查询
List<User> query=getUserWithJpaSpecificationExecutor(null,null,"张"); assert query != null;
}
private List<User> getUserWithJpaSpecificationExecutor(@Nullable LocalDateTime start,@Nullable LocalDateTime end,@Nullable String keyword){
//String, format中%为特殊字符需要再加一个%进行转义,以下格式化的结果为% {keyword} %
String nameLike=keyword==null?null:String.format("%%%s%%",keyword);
return userRepository.findAll(((root,query,criteriaBuilder) ->{
//根据传入参数的不同构造谓词列表
List<Predicate> predicates=new ArrayList<>();
if(start!=null&&end!=null){
predicates.add(criteriaBuilder.between(root.get("createTime"),start,end));
}
if(!StringUtils.isEmpty(nameLike)){
predicates.add(criteriaBuilder.like(root.get("nmine"),nameLike));
}
query.where(predicates.toArray(new Predicate[0]));
return query.getRestriction();
}));
}
较之于 JpaRepository 的查询方式,JpaSpecificationExecutor 并不需要另外定义接口,通过组合各种谓词(Predicate)构造最终的查询条件。声明:《Java系列教程》为本站“54笨鸟”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: